Once you've configured a distributor and created
a publication, the last step in configuring SQL Server replication is to create
a subscriber who will receive publication updates from the publisher.
In this tutorial, we walk through the process of subscribing to a publication,
step-by-step. The process may be accomplished either at the publisher or the
subscriber
Steps to Create Subscriber
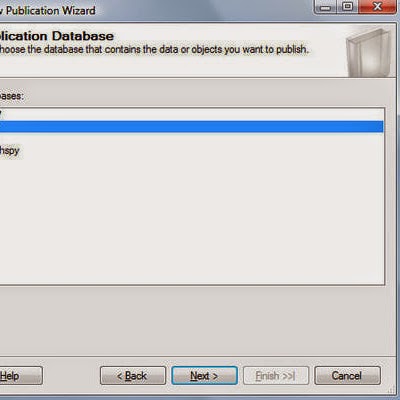
- Open SQL Server Management Studio, connect to the publishing server and expand the Replication folder.
- Expand the Local Publications folder inside of the Replication folder.
- Right-click on the publication that you wish to create a subscription to and choose New Subscription from the pop-up menu.
- The New Subscription Wizard will open. Click Next to advance past the initial screens that welcome you to the wizard and confirm the publisher and publication you selected.
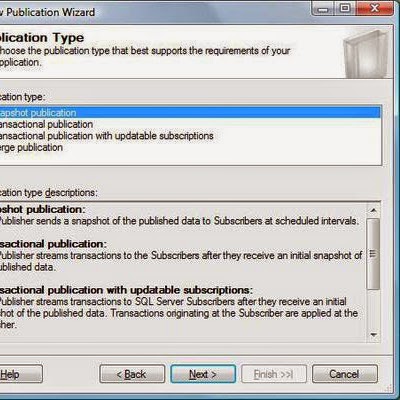
- Select whether you wish to create a push or pull subscription and click Next to continue. In a push subscription, the Distribution Agent will run on the distributor and changes will be sent out to the subscriber as they occur. In a pull subscription, the Distribution Agent will reside on the subscriber and will check in with the publisher periodically to check for available updates.
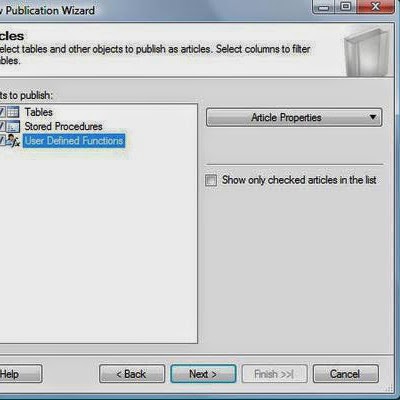
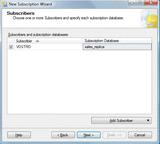
- In the next window, select the subscriber server(s) by checking the box to the left of each server you wish to receive the subscription. If the server you wish to use is not listed, click the Add Subscriber button to add it to the list. You should also select the subscription database for each subscriber using the pull-down menu to the right of each selected server. When you are finished, click the Next button to continue.
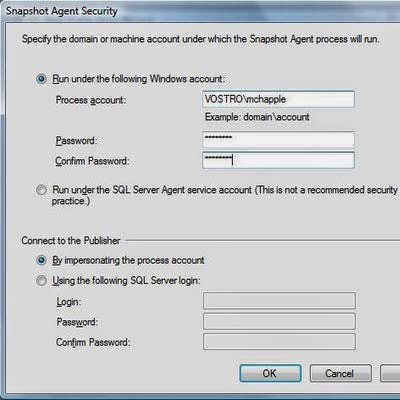
- Click the ellipses ("...") button to configure Distribution Agent Security. You will be asked to provide account information that will be used to authenticate the subscription connection. When you are finished, click the Next button to continue.
- Select a schedule for the Distribution Agent if you wish to vary from the default value of continuous distribution. Click the Next button to continue.
- Select an initialization time if you wish to vary from the default value of immediately. Click the Next button to continue.
- Click Next to accept the default value of creating the subscription immediately. Your alternative is to create a script that may be run at a later date.
- Click the Finish button to create the subscription. SQL Server will provide a status window informing you of its progress creating the new subscription.